自 ECMAScript 2015 以来,ES 将不再进行大幅度变更,而是改为每年小副更新:在每年的 3 月份,TC39 委员会将会合并当前已进入第 4 阶段的提案,并整理出一份新版的草案,然后再经过几个月的审核期之后,最终于当年 7 月份的 ECMA 大会上批准发布[1]。
而从 19 年开始,我准备在每年年初时系统地了解一下新出的特性,并顺便写一篇文章。而这一篇,就是关于今年 ECMAScript 2022 的。
今年,也就是 ECMAScript 2022 这个版本中,有 8 个提案被添加了进来;其中,就包括一直以来都充满争议的 Class Fields 提案,这个提案(及与其相关的另外两个提案)作为重头戏,我们放到最后来聊。在它之前,我们先把另外 5 个提案简单串一下。
Accessible Object.prototype.hasOwnProperty [2]
该提案中提供了一个新的方法,用于替换老的 Object 上的 hasOwnProperty 方法。
要聊这个提案,我们首先需要聊一下为什么要替换掉老的 hasOwnProperty 方法,也就是说,hasOwnProperty 有什么问题。
而其问题就在于:它是一个 Object 原型上的方法。而大家也知道,JavaScript 中的对象又实在是太过于灵活,用户可以在对象上动态定义任何属性。这样一来,就会导致 hasOwnProperty 有可能会被覆盖掉。
因此若想要避免这个问题,通常就需要从 Object 的原型对象中将这个方法拿出来,然后通过 .call 的方式去调用它,就像这样:
const hasOwnProperty = Object.prototype.hasOwnProperty
if (hasOwnProperty.call(object, "foo")) {
console.log("has property foo")
}
这么写当然会很繁琐,因此通常大家都会将这段代码封装成一个方法来调用:
function hasOwn() {
const hasOwnProperty = Object.prototype.hasOwnProperty
if (hasOwnProperty.call(object, "foo")) {
console.log("has property foo")
}
}
但是每个项目或库每当需要用到它时,都需要封装这么一个方法的话。总这么搞,确实也不是个事。
所以这个时候,就该我们的提案出场了。
这个提案很简单,它只是在 Object 的类上添加了一个静态方法,名为 hasOwn。其逻辑与 hasOwnProperty 方法完全相同,也是用于判断某个对象自身当中是否拥有某个属性,但在使用上却要便利许多:
if (Object.hasOwn(object, "foo")) {
console.log("has property foo")
}
最后,这里唯一需要注意一点的是,若给 object 参数传入的值是 undefined 或 null,那么该方法将会抛出一个 TypeError 异常:
Object.hasOwn(undefined, 'foo')
// Uncaught TypeError: Cannot convert undefined or null to object
貌似这是最快达到 Stage 4 的提案(2021年4月进入 Stage 1,同年 8 月就达到 Stage 4 了),而这之前最快达到 Stage 4 的提案是可选的 catch 绑定。
.at() [3]
这个提案的背景是这样的。
就是在开发时,我们有时会需要访问数组中的最后一个元素,并通常会写出这样的代码:
const arr = [1, 2, 3]
arr[arr.length - 1]
但很显然,这种写法稍显繁琐。而且因为这样写需要先将数组赋值给某个变量后才能访问,因此它对匿名值也很不友好。
那么有哪些方式可以解决这个问题呢?有两种,一种是在语法上提供支持,而另一种则是提供一个工具方法。
通常来说,在语法上提供支持是最好的方式。比如,在 Python 这门语言中,它就支持直接使用负数来索引数据元素:
arr = [1, 2, 3]
arr[-1] # => 3
但在我们的 ECMAScript 中,却没有办法直接照搬这种语法。因为按照目前的规范,这样做的结果应当是访问对象中名为 "-1" 的那个属性的值:
arr = [1, 2, 3]
arr[-1] // e.q. arr["-1"]
因此最终,该提案添加了一个 at 方法,这个方法可以根据所传入的索引值返回对应的元素,而且支持负数索引值:
const arr = [1, 2, 3]
arr.at(0) // => 1
arr.at(-1) // => 3
若是传入负数,则索引值按 arr.length + N 进行计算,因此 -1 就等于 arr.length + (-1),也就是 arr.length - 1。
另外,该方法其实是被添加到了所有内置的可索引对象的原型中,因此我们不但可以在数组中使用它,甚至也可以用在字符串中:
const str = 'abc'
str.at(0) // => 'a'
str.at(-1) // => 'c'
以及类型化数组中:
const int8 = new Int8Array([1, 2, 3])
int8.at(0) // => 1
int8.at(-1) // => 3
一开始,该提案想要添加的方法名是
.item(),但之后发现这个方法名已经被一些库使用了,而该提案与这些库并不兼容,因此改为了.at()。但再之后又发现,有一个名为「BrickLink」的乐高交易网站,他们把一个数组实例用作 key-value 集合(就像
arr[key]),并使用"at"作为 key。而当火狐支持了.at()方法后,这个网站就挂了……(唔,至少是他们网站的搜索功能挂掉了……)。当浏览器的开发人员们发现了这个问题后,他们曾一度想过要将方法名改为
.itemAt(),但很不幸,早年间有一个名为 ExtJS 的框架,常被用来开发后台项目,然后哪,这个框架中已经用到了这个方法名,因此.itemAt()也不能用。最终,提案的作者通过 BrickLink 网站的用户反馈功能联系到了他们的开发人员,然后他们修复了这个功能(据说他们是重写了网站)。
Error Cause [4]
该提案与错误对象有关。
它让我们在创建错误对象时,除了可以传入一个消息之外,还可以额外传入一个配置对象,该配置对象中可以指定一个名为 cause 的属性,这个属性代表产生该错误的源信息,而它的值,可以是另外一个 Error 对象,也可以是任何其它类型的值:
new Error('message', {
cause: otherError
})
相应的,在所创建出的错误对象中,也会有一个 cause 属性:
const error = new Error('message', {
cause: otherError
})
error.cause // => otherError
那么,现在的问题是,它有什么用呢?
同样举个例子,假设我们有一个 readJson 方法,用于读取、解析并返回指定 JSON 文件中的内容,代码如下所示:
function readJson(path) {
const file = readFile(path)
return JSON.parse(file)
}
这里读取文件的操作是使用了一个叫做 readFile 的方法,它会同步地读取文件,并按 utf-8 编码将文件内容解析为字符串。而 JSON 数据的解析则直接用了原生提供的 JSON.parse 方法。
现在,我们希望当文件读取失败,或数据解析失败时,在所抛出的异常消息中带上文件路径,方便排查问题。显然,若要做到这一点,我们需要将 readJson 中的这两行代码用 try...catch... 包裹起来,并在 catch 中重新组织异常消息,就像这样:
function readJson(path) {
try {
const file = readFile(path)
return JSON.parse(file)
} catch (error) {
throw new Error(
`read json file failed, file: ${path},
cause: ${error?.message ?? error}`
)
}
}
但这样做会有两个问题。
首先,很明显,因为 ES 允许抛出任何类型的错误值,因此若想要安全地从原始错误中获取消息字段,则无论如何都是要麻烦一些的(error?.message ?? error)。
另外,更重要的是,原始错误中的堆栈信息丢失了,如果这个错误是从 readFile 方法中抛出的,那么我们将无法立即知道它被抛出的位置,这很有可能会对我们排查问题带来影响。
而这两个问题,便是 Error Cause 提案所要解决的问题。借助这个提案中所提供的功能,我们可以将屏幕上的代码重写为这样:
function readJson(path) {
try {
const file = readFile(path)
return JSON.parse(file)
} catch (error) {
throw new Error(
`read json file failed, file: ${path}`,
{ cause: error }
)
}
}
可能看起来没有太多改变,但其结果却有很大不同。
首先,我们不再需要关心原始错误的类型,直接将它扔到我们新创建的 Error 对象中即可。
另外,因为新创建的 Error 对象中关联了原始错误,因此所有的原始错误信息都不会丢失,包括最重要的堆栈信息。
如此,便能解决刚才所说的那两个问题了。
当然,仅是将这些错误信息组织起来并不够,还需要相关工具(如浏览器开发者控制台)遵循这一约定,在展示错误信息时,将错误对象中所关联的其它错误的相关信息一并展示出来。
而目前在 FireFox 中,这已经实现了。
若在 FireFox 中打印一个错误对象,那么将会在浏览器控制台中看到这样的内容。可以看到所输出的异常信息中有一个 Caused by 子段落,这就是被关联的异常信息:

而 Chrome,则至少在我写这篇文章时,它还没有支持这一特性。
RegExp Match Indices [5]
该提案可以让我们拿到正则表达式所匹配到的子字符串在原字符串中的位置信息,尤其是可以拿到每个捕获组所匹配部分的位置信息。
首先,它为 正则表达式 添加了一个新的标识符 /d:

然后,当你为某个正则表达式声明了该标识符,并拿着它去调用那些会返回匹配信息的方法(比如 RegExp.prototype.exec()、String.prototype.match()、String.prototype.matchAll())时,所返回的匹配信息中将会多出一个 indices 属性。
这里让我们举个例子,假设我们需要匹配一段 JavaScript 代码文本:
'const k1 = 666'
以期望找出其中的变量声明部分(如 const k1 或 let k2)。
那么我们可以设计一个这样的正则表达式:
/(const|let|var)\s+([a-z][a-z0-9]*)/
这里是做了简化的,实际的正则会比这个要复杂得多。
然后给它加上 /d 标识符,并调用它的 exec 方法:
const regex = /(const|let|var)\s+([a-z][a-z0-9]*)/d
const match = regex.exec('const k1 = 666')
那么所得到的 match 信息,将会是如下所示:
const regex = /(const|let|var)\s+([a-z][a-z0-9]*)/d
const match = regex.exec('const k1 = 666')
// => match: [
// 0: 'const k1'
// 1: 'const'
// 2: 'k1'
// length: 3
// input: 'const k1 = 666'
// index: 0
// groups: undefined
//
// indices: [
// 0: [0, 8] // 'const k1'
// 1: [0, 5] // 'const'
// 2: [6, 8] // 'k1'
// ]
//
// ]
可以看到,match 信息中将会多出一个 indices 属性,而它的值同样也是一个数组。这个数组中所包含的便是这次匹配中每个匹配结果在原字符串中的起止位置。
比如 match[0] 是整个正则表达式所匹配到的结果 const k1,那么其在原字符串中的位置则是 match.indices[0] 的值,也就是 [0, 8]。
再比如 match[1] 是第一个捕获组所匹配到的结果 const,其起止位置则是 match.indices[1],也就是 [0, 5]。
其余结果依此类推。
另外若某个捕获组没有匹配,则该捕获组在 indices 中对应的值将是 undefined。
命名捕获组
另外,为了方便使用,该特性也为命名捕获组提供了相应的支持。
如果我们继续在刚才示例的基础上,为正则表达式中的捕获组加上名字:
const regex = /(?<keyword>const|let|var)\s+(?<identifier>[a-z][a-z0-9]*)/d
const match = regex.exec('const k1 = 666')
那么 indices 中将会额外多出一个 groups 属性:
const regex = /(?<keyword>const|let|var)\s+(?<identifier>[a-z][a-z0-9]*)/d
const match = regex.exec('const k1 = 666')
// => match: [
// 0: 'const k1'
// 1: 'const'
// 2: 'k1'
// length: 3
// input: 'const k1 = 666'
// index: 0
// groups: { keyword: 'const', identifier: 'k1' }
//
// indices: [
// 0: [0, 8]
// 1: [0, 5]
// 2: [6, 8]
//
// groups: {
// keyword: [0, 5]
// identifier: [6, 8]
// }
// ]
//
// ]
当然,其中每个 key 所对应的,就是这个捕获组所匹配到的结果的起止位置,同样若某个捕获组没有匹配,则对应的值将是 undefined。
String.prototype.matchAll()
最后,再稍微提一下字符串中的 matchAll 方法。
若是使用该方法获取所有匹配信息,那么每个匹配信息中都会有一组 indices。
比如像这个示例中:
const regex = /(const|let|var)\s+([a-z][a-z0-9]*)/dg
const str = `
const k1 = 666
let k2 = 'name'
`
const matches = str.matchAll(regex)
第一次调用 matches.next() 方法所拿到的第一个 match 信息中,会有一个 indices 属性:
matches.next()
// => [
// 0: 'const k1'
// 1: 'const'
// 2: 'k1'
// length: 3
// input: ...
// index: 5
// groups: undefined
//
// indices: [
// 0: [ 5, 13] // 'const k1'
// 1: [ 5, 10] // 'const'
// 2: [11, 13] // 'k1'
// ]
// ]
而第二次调用 matches.next() 方法,拿到的第二个 match 信息中,也会有一个 indices 属性:
matches.next()
// => [
// 0: 'let k2'
// 1: 'let'
// 2: 'k2'
// length: 3
// input: ...
// index: 24
// groups: undefined
//
// indices: [
// 0: [24, 30] // 'let k2'
// 1: [24, 27] // 'let'
// 2: [28, 30] // 'k2'
// ]
// ]
Top-level await [6]
偶尔,我们可能会需要在模块被加载时立即执行一些异步操作,比如说:下载一个文件,或是加载一份配置,然后等待这些异步操作完成之后再去执行它后面的代码。嗯,就像下面这个 async-config 模块中所做的这样:
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
fetch('/api')
.then(response => response.json())
.then(config => {
// do something ...
})
但大家可以看到,这里我们使用的是 Promise API,相比起我们现在常用的 async/await,这种写法要繁琐许多。
因此,我们可能会尝试把代码改成这样:
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
const response = await fetch('/api')
const config = await response.json()
但在之前,规范中明确要求 await 关键字只能用在 async 函数中,所以很明显这样写是不对的。那怎么办呢?我们可以用一个立即调用函数把这段代码包起来,就像这样:
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
(async () => {
const response = await fetch('/api')
const config = await response.json()
})()
嗯,这已经能满足我们当前的需求了,虽然仍会稍微繁琐一点点,但相比 Promise API 也确实已经好很多了。
在现实当中,当我们面对这种场景时,大多数时候我们也都是这样做的,包括我自己也是这样做的。
但当这个场景继续扩展时,依然还是会有一些新的问题出现。
比如,如果我们想在这个模块中导出所加载到的配置数据,以供其它模块使用,那要怎么做呢?也许我们可能会这样做:
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
export let config
(async () => {
const response = await fetch('/api')
config = await response.json()
})()
也就是直接在函数外声明一个变量,同时导出它,然后等待配置数据加载到后,将其赋值给这个变量。
这样做很简单,但可能并不好,让我们实际去使用一下这个模块就能发现它的问题,比如:
// --------------------------------------------------
// main.js
// --------------------------------------------------
import { config } from 'async-config.js'
setTimeout(() => {
console.log(config)
}, 100)
在这个 main.js 文件中,我们导入了 config,并在等待 100 毫秒后打印了一下它的值。
那么它会打印出什么内容呢?
我们并不知道,因为可能这个时候配置数据已经加载完了,那么会正确打印出来;但也有可能还在继续加载中,那么就会打印出 undefined。
所以很明显,这种方式的可用性非常不好。
那要怎么做呢?也许我们可以直接把加载并返回配置数据的 promise 作为导出项,就像这样:
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
export let loadConfigPromise = (async () => {
const response = await fetch('/api')
return await response.json()
})()
我们重新定义了一个导出变量,命名为 loadConfigPromise,并将立即调用函数的返回值(也就是一个 promise)赋值给它。
然后在其它模块中,就可以导入这个 promise,并等待它加载完毕,以此来确保成功拿到配置数据:
// --------------------------------------------------
// main.js
// --------------------------------------------------
import { loadConfigPromise } from 'async-config.js'
loadConfigPromise.then((config) => {
console.log(config)
})
但显然,这会导致每个需要用到这份配置数据的地方都要通过异步方式去拿到它。而且要考虑到,在实际的项目中,我们可能还需要妥善处理好加载中及加载失败的状态。
所以这种方式有的时候可能也不太好。
那有什么办法可以解决这个问题吗?有的,还记得我们刚才在刚开始时,是怎么把 Promise API 转写成 await 的吗?
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
const response = await fetch('/api')
const config = await response.json()
其实这就是答案,设想一下,如果 ECMAScript 允许在模块的顶级使用 await 关键字,并让模块加载器在加载该模块时等待这些异步操作,以便可以让我们直到配置数据加载完成之后再导出它,然后其它模块在导入该模块时,也等一下,那不就可以了嘛:
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
const response = await fetch('/api')
export const config = await response.json()
// --------------------------------------------------
// main.js
// --------------------------------------------------
import { config } from 'async-config.js'
console.log(config)
可以很明显地看到,代码比之前要直白了许多。
而这,就是「顶级 await」这个提案作做的事情。
语法规则
下面详细说一下它的规则。
首先,「顶级 await」,顾名思义,它仅在模块的「顶级」生效。
你可以假设整个模块中的代码都被包裹在了一个巨大的 async 函数中,而我们可以在这个函数的函数作用域及其中的块级作用域中使用 await 关键字,这就是所谓的「顶级 await」:
// --------------------------------------------------
// async-config.js
// --------------------------------------------------
(async () => {
const response = await fetch('/api')
export const config = await response.json()
})()
另外要注意,它只能用在 ES 的模块中,对于普通脚本,无论是在浏览器中加载的普通脚本,还是 Node.js 中的 Common JS 模块,都不能用。当然,也依然不能用在非 async 的函数中。
这就是顶级 await 的使用规则。
模块加载策略
接着要聊一下模块的加载策略,当你在一个模块中使用了顶级 await 后:
- 首先,该模块将在其中的所有顶级 await 都切换为成功状态,并且所有代码都执行完毕后,才会视为加载完毕;
- 若在该模块中导入了其它模块,那么该模块将等待其所导入的所有子模块全都加载完毕后,才会开始执行自身的代码;
- 另外,模块加载器会尽可能并发加载。
为了帮助大家更好地理解这三条规则,我们打个比方,假设我们有 main、a 和 b 三个模块,分别命名为 main.js、a.js 和 b.js,它们的代码如下所示:
// --------------------------------------------------
// main.js
// --------------------------------------------------
import { a_data } from './a.js'
import { b_data } from './b.js'
console.log('main start', a_data, b_data)
console.log('main done')
// --------------------------------------------------
// a.js
// --------------------------------------------------
console.log('a start')
export a_data = await load('/a_data')
console.log('a done')
// --------------------------------------------------
// b.js
// --------------------------------------------------
console.log('b start')
export b_data = await load('/b_data')
console.log('b done')
其中 main 模块依次导入了 a 模块和 b 模块,而 a、b 两个模块分别使用顶级 await 各自加载了一份数据并导出,另外这三个模块都分别打印了一些日志。
然后,让我们看一下模块加载器是如何加载这三个模块的。
首先,引擎会加载 main 模块的代码:

然后解析它,这个过程将会发现它导入了 a 模块和 b 模块,因此,引擎接着开始加载这两个模块:
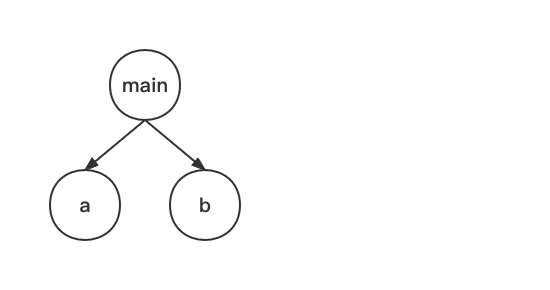
加载并解析完 a 模块后,由于它没有再导入其它模板,因此引擎开始执行它的代码:

但由于 a 模块中包含顶级 await,那么当代码执行到 await 这一句时,将开始等待它:

此时,a 模块的装载操作将会挂起,引擎改为开始执行 b 模块:
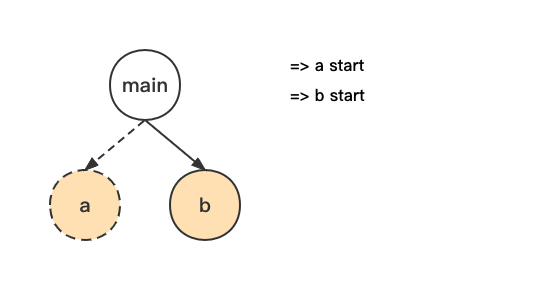
b 模块中也包含顶级 await,因此它的装载操作也会被挂起:

此时再也没有其它模块需要处理了,引擎可以歇一会了。直到其中有一个模块的异步操作执行完成,这里假设是 b 模块,那么将会继续执行 b 模块中的剩余代码,然后 b 模块装载完成:

再过不久,a 模块中的异步操作也执行完成,开始执行其后续代码,接着,a 模块也装载完成:
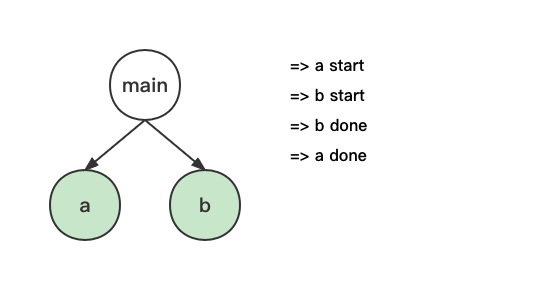
当这两个模块都装载完后,将开始执行 main 模块中的代码:

由于 main 模块中的代码都是同步的,因此待其中的代码执行完后,所有模块都将装载完成:
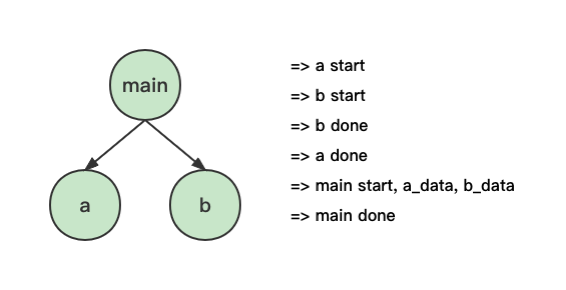
看,就是这样,是不是挺简单的?
争议
但是刚才也讲到了,这个提案是有争议的,我们还要聊一聊它有争议的一面。
首先,大家也看到了,顶级 await 会延迟模块的装载。虽然引擎会尽可能并发装载模块,但却很容易打破,假设在刚才的例子中,若 a 模块也依赖了 b 模块,新的依赖关系图如下所示:
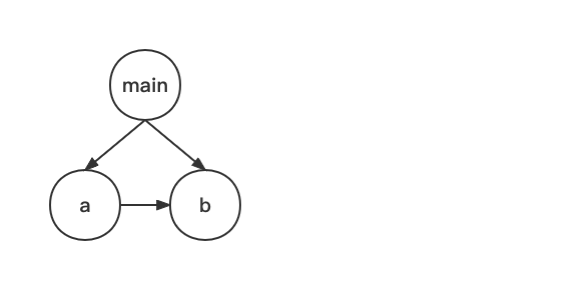
那么显然只有当 b 模块加载完成后,a 模块中的代码才能开始执行。而不再会像之前那样并发加载这两个模块了。
而鉴于在导入方式上,导入使用顶级 await 的模块与导入普通模块并无区别,因此这种问题其实还挺容易触发的。项目中使用顶级 await 的模块越多,这种问题就可能越容易出现。
所以建议大家在实际项目中,切不可图一时方便,随意使用顶级 await。
甚至有可能在你添加顶级 await 的时候,在当时的项目中并没有什么问题,但随着时间推移,项目迭代,模块越来越多,它们之间的依赖关系也在不断变化之后,可能就会出现模块装载耗时较长这种问题了,因此请一定要慎重。
另外项目中若有多个模块使用了顶级 await,也请尽量能够并发装载这些模块,比如在入口模块中分别按序导入它们。
死锁
另外,还有一个死锁的问题,如果有两个模块互相通过顶级 await 动态导入对方,那么模块装载将会陷入死锁,比如这样:
// --------------------------------------------------
// a.js
// --------------------------------------------------
await import('./b.js')
// --------------------------------------------------
// b.js
// --------------------------------------------------
await import('./a.js')
很明显,a 模块需要等待 b 模块装载完毕,而 b 模块却也在等待着 a,相互等着,最终两个模块永远都无法装载完毕,这就是死锁。这种问题出现的概率应当不高,大家知道这种情况存在,平时使用时稍微注意一下就是了。
异步操作失败
最后,还剩下一个刚才一直没有提到问题,就是如果异步操作失败,且没有捕获该错误的话会怎么样呢?
比如当 a、b 两个模块都在等待异步操作,此时若 a 模块的异步操作失败了:
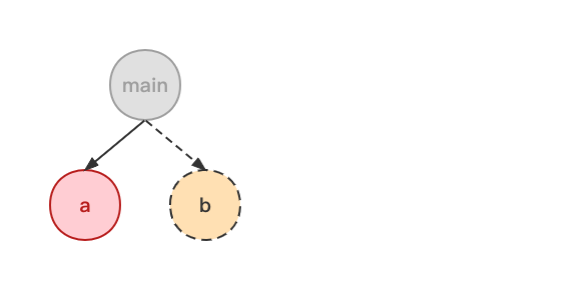
那么,从导入该模块的父模块开始,直到入口模块,全都不会执行,这一点和普通模块在执行时出现未捕获异常的处理方式是一样的。
不过还需要注意的是,由于并发装载的存在,如果在某个模块加载失败时,有其它模块正在等待其所发出的异步操作。那么在不同的 JS 执行环境中,它的结果可能是不一样的。
在浏览器中,由于页面不会在模块加载失败时自动关闭,因此当那些已发出的异步操作结束时,正在等待它们的模块会继续执行,并完成装载,虽然此时依赖它们的父模块已经死掉了。
而在 Node.js 中,由于未捕获异常最终会导致进程关闭,因此那些正在等待异步操作的模块,将会一起被销毁。
Class Fields [7]
好了,现在到了今年最重要的一个提案了,也就是「Class Fields」。
顾名思义,这个提案允许我们在类中声明属性,而且不但可以声明公有属性,也可以声明私有属性。
如果大家有在用 TypeScript,那么应该有在 TypeScript 中定义类时声明过属性,并且对它的语法和行为也都已经有一些了解了。
但请听我说,TypeScript 中的类属性,与这个提案在 ECMAScript 中所加入的类属性,是完全不同的两种东西,无论是公有属性、还是私有属性。
好了,让我们把它们拉出来溜溜吧。
属性声明
首先是声明公有属性,它的语法很简单。
我们只需要在类的定义块中直接写一个标识符,就算是完成了一个属性的声明:
class A {
x
}
如果想为属性指定初始值,那么就在属性名后添加一个等号,然后再跟一个表达式就可以了:
class A {
x = 0
}
这里稍微需要注意一点的是,我们在计算初值的表达式中是无法引用其它属性的,比如以下面这段代码为例:
const x = 1
class A {
x = 0
y = x
}
这里 A 类中 y 属性的初始值会是 1,而不是 0。
其原因也很简单,其实就和我们在写对象字面量时,无法在属性值表达式中引用其它属性一样:
const x = 1
const a = {
x: 0,
y: x,
}
所以说,类的定义块并不是一个代码块,它只是一个用来定义「类」字面量的一个语法元素而已:
class A {
x
y = 0
}
虽然为类的属性赋予初值时用的是「等号」字符,这让它看起来与变量赋值语句非常相似,但其实完全是两码事:
x = 0
y = x
class A {
x = 0
y = x
}
不过,这只是语法上的一点小问题。
真正的大问题,是类属性的语义。
属性的语义
刚才也提到了,TypeScript 中的类属性,和该提案中的类属性是完全不同的两种东西。而它们之间的不同,就是在语义上。
我们先来看一下 TypeScript 中的类属性。这是一段 TypeScript 代码:
class A {
x
y = 0
}
如果我们将它编译成 ES2015(使用命令 tsc demo.ts --noImplicitAny false --target es2015 ),那么编译出的代码是这样的:
class A {
constructor() {
this.y = 0
}
}
可以看到,因为 x 属性仅只是声明,并未指定初始值,因此在编译时被忽略了。
而最重要的,则是 y 属性被编译成了构造函数中的 this.y = 0 这一句。
这个,就是 TypeScript中对于属性赋值所设定的语义行为,也叫做 [[Set]] 语义。
那么,该提案中的类属性的语义与此又有什么不同呢?
再让我们看一下刚才的这段 TypeScript 代码:
class A {
x
y = 0
}
现在我们把它视为是 ES2022 的代码,因为语法上完全相同,所以我们可以这样做。接着,假设我们有另外一个编译器,它可以把 ES2022 编译成 2015 版本(比如 babel),那么编译出的代码将是这样的:
class A {
constructor() {
Object.defineProperty(this, 'x', { value: undefined, ... })
Object.defineProperty(this, 'y', { value: 0, ... })
}
}
可以看到,这与 TypeScript 基于相同代码编译出来的结果完全不同。
首先,这两个属性都基于 defineProperty 被定义到了 this 中,并被赋予了初始值。
而 x 属性也并未被忽略,且初始值是 undefined。
这个,就是该提案所引入的类属性,也就是未来 ES 中的类属性的语义行为。当然,这种语义也有一个名字,叫做 [[Define]] 语义。
[[Set]] 语义, [[Define]] 语义
说实话,如果将「属性声明」理解为「为类定义一个属性」,那么使用 [[Define]] 语义其实是合适的。
但它确实会产生一些很棘手的现实问题。
一方面,也是最重要的,让我们考虑一下类的继承关系。如果有一个父类和一个子类,然后它们都声明了同一个属性,那么按照 [[Define]],子类将会覆盖掉父类对该属性的声明。比如这段代码:
class A {
x = 0
get y() {
return Math.random()
}
}
class B extends A {
x
y
}
若我们执行这段代码,并 new 了一个 B 类(也就是子类)的实例。
那么在该实例对象中,x 属性的初始值将会是 undefined,而不是 0;
而 y 属性也将是一个普通属性,访问它时不会调用到 A 类(也就是父类)中的那个 get 方法,并且 y 属性也将会是可写的。
而这,将会导致我们之后若采用面向对象编程的方式进行开发的时候,有时可能要额外当心一些。
如果你在实现一个类,而该类有可能会被继承,那么请尽可能避免该类中的属性有可能会被不小心覆盖掉。
而对于子类的实现者,有可能你要相比以前要更加地注意不要一不小心把父类的属性定义给覆盖掉。
OK,这是一方面的问题。
而另一方面,是对社区的影响,正如刚才大家所看到的,该提案会导致 TypeScript 与 ECMAScript 之间出现不一致的行为,这将使得部分 JavaScript 代码再也无法安全地迁移到 TypeScript 中,当然,TypeScript 提供了相应的配置项,允许你将其默认的 [[Set]] 语义切换成 [[Define]] 语义,但为至少也要求你知道有这么一档子事,也知道有这么一个配置项不是。
同时,这也会导致各编译器的处理行为也出现不一致,比如 babel 也支持 typescript,但这两者基于默认配置所编译出来的代码将是不一样的。
好了,不管怎么说,公有属性的事我们就聊这么多了。下面开始聊私有属性。
私有属性
私有属性的语法也很简单,如果要声明一个属性是私有的。那么只需要在属性名前添加一个 # 号字符作为前缀就可以了,除了这个 # 号之外,其它都和公有属性一样:
class A {
#x
#y = 0
}
当然,get/set 属性、以及方法也都可以声明为私有的,也是一样在属性名或方法名前加一个 # 号:
class A {
get #z() {
// ...
}
set #z(val) {
// ...
}
#add() {
// ...
}
}
而访问私有属性也很简单,就直接访问它就好了:
class A {
#x = 0
add() {
this.#x += 1
}
}
但既然人家叫做「私有属性」,那么对它的访问肯定是有限制的。这个限制就是:你只能在类的定义块中,访问其中所定义的私有属性,而在类的定义块的范围之外,是不允许访问的。 比如这段代码:
class A {
#x = 0
}
const a = new A()
a.#x
同样,若是想要访问一个未声明的私有属性,也是不允许的,再比如这段代码:
class A {
add() {
this.#x += 1
}
}
而且,这些限制是语法层面所做出的限制。
也就是说,刚才这两段代码在语法解析时就会直接报语法异常。而不是等到代码开始运行,并执行到访问操作那里时才会触发报错。
另外,既然是语法层面的限制,那么私有属性将仅支持使用 . 操作符进行访问,动态访问什么的,自然是想都不要想。
因此像这种代码:
class A {
add() {
this.#['x'] += 1
}
}
会直接报语法错误。
而像这种代码:
class A {
#x = 0
add() {
this['#x'] += 1
}
}
它递增的其实是对象中名为 #x 的字段的值,而非私有属性。
私有性
当然,也得益于这些限制,私有属性的「私有性」实现的特别好,我们没有任何手段,可以让我们在类的定义块之外,创建或访问任何私有属性。
一个类中所声明的所有私有属性,相对于外界来说,是完全隔离的,甚至相对于这个类的子类或父类,也是这样。
因此,我们可以在父类和子类之间,安全地声明任何同名的私有属性,互不冲突(这一点和公有属性是完全相反的):
class A {
#x = 0
}
class B extends A {
#x = 1
}
静态公有属性, 静态私有属性
而与公有属性和私有属性相对应的,我们也可以在类的定义块中声明静态公有属性和静态私有属性,只需要在属性名前使用 static 关键字修饰即可:
class A {
static x
static #y = 0
}
而且,对于静态私有属性,也同样只能在类的定义块中访问。
Ergonomic brand checks for Private Fields [8]
这是一个与私有属性配套的小提案。它让 in 运算符支持检查指定的对象中是否包含某个私有属性。
之所以添加这么一个功能的原因是,毕竟 ECMAScript 是一门动态类型的语言,因此虽然对私有属性本身的访问是在语法解析时就直接做了的,但要知道,用来访问私有属性的对象却并不一定是当前类的实例,因此仍然会出现访问私有属性失败的情况:
class A {
#x = 0
getX() {
return this.#x
}
static add(a1, a2) {
return a1.#x + a2.#x
}
}
const a = new A()
A.add(a, {})
a.getX.call({})
这段代码中的最后两句都会在运行时抛出 TypeError 异常。
也是因此,TC39 就非常用心地想了个辙,让 in 操作符支持了私有属性。如果有必要的话,我们可以检测一下指定对象中是否包含某个私有属性,就像这样:
class A {
#x = 0
static add(a1, a2) {
if (#x in a1 && #x in a2) {
return a1.#x + a2.#x
}
return 0
}
}
Class Static Block [9]
然后这最后一个提案也是与私有属性配套的,也很简单。
它引入了一个新的语法元素,让我们可以在类的定义块中使用 static 关键字修饰一个代码块,然后这个代码块将会在类被创建后立即执行,而在执行时其中的 this 便是这个类本身:
class A {
static x
static {
console.log('A.x is', this.x)
}
}
这段代码等同于这样:
class A {
static x
}
console.log('A.x is', A.x)
那它有什么用呢?当然有用,它可以用来访问静态私有属性:
class A {
static #x
static {
console.log('A.x is', this.#x)
}
}
刚才也说到了,无论是实例对象上的私有属性,还是类本身上的静态私有属性,都只能在类的定义块中访问。
因此如果你需要在类创建后立即执行一些代码,而其中需要访问类的静态私有属性,那么你就可以用到它了。
结语
愿使用 Class Fields 的人能够开心,愿北京的疫情能够快点过去。